
Updated: April 25, 2024 - 7 min read
Editor’s note: You’re about to read an extract from our new book “Ship It 2.0”. You can get the full book here.

Jason Nichols is a #ProductCon New York speaker and currently leads four cross-functional teams as Walmart’s Director of AI.
Most AI problems can be broken down into four groups. You’re either trying to classify something, count something, find out what’s important about something, or group things together. It’s important to think about what model you want to use, why you want to use it, and whether or not it’ll answer your question, which at the end of the day is what you want AI to do.
Step 1: Ask your question

Different models answer different kinds of questions. They all have different KPIs, you’ll talk about them in different ways, and their properties are different:
Regressors answer “How many?”
Classifiers answer “What’s that?”
Detectors answer “What are ‘these’ in this?”
Dimensionality Reducers answer “What makes these things different?”
Clustering Algorithms answer “How can I make groups of these?”
When you set out to build an AI system you need to know what question you’re asking, and one question per model is key.
When you’re training an AI model you need to use a loss function, which takes into account many different potential objectives for your data.
If you want to ask ‘how many items are there?’ don’t add additional properties like ‘how blue is it?’
Step 2: Consider how AI learns

Different models have different ways of learning:
Some are supervised and need labeled data
Some are unsupervised and determine their own labels
Some take feedback from their environment and learn via reinforcement
Models can also have online and/or offline learning modes (Siamese Networks use both: Training is offline but enrolment is online.)
Once you know which question you’re asking, the next step is to ask yourself how your machine will learn:
Can humans provide feedback? You need to know whether you’ll be getting that real-time feedback or not.
Do you have downtime to train? If your system has to be online 24/7 and can never go offline you have to figure out how you’re going to handle that. A lot of Deep Learning models require intensive GPU training. While it can be done in the background separately from your production stream, it’s still something to factor in.
How will you build CI/CD? This is more of an engineering challenge, but it’s definitely something for PMs to consider. What are the tests that you want the new model to pass? What are the KPIs that are absolute blockers to releasing production? Without capturing those requirements and building them into your production pipeline, you’ll find models sneaking in which do slightly better than previous versions, but which fail catastrophically in terms of business objectives.
Can you make use of a Knowledge Base? The concept of a Knowledge Base in AI is very old. You can think of AI models as very stupid rats. They have very little neural capacity, they can’t think too hard. So if you’re able to give them flashcards that they can reference, they tend to do very well.
How will you know if the model is meeting the business needs? This links back to your CI/CD. If you’ve documented your requirements and built them into your production pipeline whilst keeping an eye on your KPIs, you’ll get results.
Step 3: Implementing your AI

Once you’ve got the question and model type from Step 1, and the training method(s) from Step 2, it’s time to think about how you’ll implement this service.
In the AI lifecycles they use at Walmart, they have a System Checklist based on Agile methodologies:
Feature selection
Model architecture
Initial training & transfer learning
Model persistence
Evaluation and CI/CD
Inference
Logging & Sampling
Annotation
Cross-validation
Source rating
Aggregation
Normalization and sanitization
Training
Knowledge base update
Ground Truth

Jason quotes Voltaire, saying:
““Doubt is unpleasant, but certainty is absurd.””
When it comes to Ground Truth…there is none.
There is always a margin of error in every human annotation, and if you don’t take that into consideration as you begin to build these models, you’re going to have a bad time.
Annotators and Algorithms are just different Agents.
Humans are lazy, sloppy, and imprecise. And worse…they build algorithms!
There’s a lot of work being done to understand the source of error in annotation, the biggest being fatigue, coordination, misaligned incentives, and unconscious bias.
How Can Product Drive AI?

The big things for PMs to understand to help make AI effective are that the costs and benefits associated with the confusion matrix define business value.
PMs should also communicate probabilities and confidence to stakeholders so they can make informed decisions.
You should also make sure your work is hypothesis-driven and experimentally validated, and think in terms of ROI both for improving features and confidence.
Another way for PMs to boost their AI knowledge is to learn the basic terms. Here are the most commonly misused or conflated terms:
Accuracy: When you ask the model for an inference, what percentage of the time is it right?
Precision: When the model says ‘X’, how often is that correct?
Recall: When ‘X’ occurs, how often does the model catch it?
Incidence rate: How often does ‘X’ occur?
Error rate: How often is the model wrong? (this is the opposite of accuracy)
Incidence rate is one of the most important things to be sure of as a Product Manager.
If you don’t know what the incidence rate is, it’s very difficult for engineers to adequately design and test systems and build the training pipelines.
Before you approach AI, you should do at least some base research to approximate this incidence rate.
Error and Confusion: What PMs Need to Know

If there is only a 10% incidence rate (represented by the yellow box) and a 90% negative rate, if the model is right 80% of the time, that means that its maximum precision is 33%. It can never achieve a precision rate higher than this, because it’s going to be wrong 2/10 times.
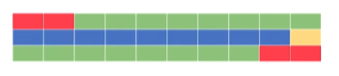
And most likely, those two times are going to be when an incidence doesn’t occur, so it’s going to say that there were three, when there was only one.
This is a mathematical relationship that cannot change, despite some people saying “just tighten up the precision, don’t worry about accuracy!” Understanding this relationship is incredibly important.
It’s also important to visualize a confusion matrix, which essentially tells you ‘When I say X, how often do I mean Y?’ This is the key thing to understand for a PM, as there are different costs associated with different confusions.
Good Statement vs Bad Statement

To give us a more concrete understanding of how to talk about precision and accuracy, and keep your language more grounded in statistics, Jason shows us an example of a good statement versus a bad statement:
✔ “We believe the model’s precision is between 80 and 90% with 95% confidence based on a production experiment with 500 examples.”
Measured in production
Real metric
Communicated uncertainty
High and transparent sample size
Replicable
✘ “The model’s accuracy is 99%”
No it isn’t
What was the sample size?
How does it generalize?
How did you measure that?
Why does this matter so much? When communicating complicated concepts in AI, people will always take away a simplified version of what you said, so if you give them something simple, their understanding gets even simpler!
The first statement gives them all the information they need to know, the second is not a meaningful statement. What they’ll take away from the second statement is ‘yeah it’s good.’
Good Requirement vs Bad Requirement

✔ “The business needs the systems to have a minimum precision of 0.95 and recall of 0.90, a maximum latency of 5s and process 10 streams per GPU.”
Tells me false positives are worse for the business than false negatives
Tells me about the compute available
A real definition of done
Can still be refined by adding information on data and mission
✘ “Just make it right.”
I can make anything right with enough data and compute
Need to understand tradeoffs, constraints, overall mission
Now, you’ll have everything you need to successfully build products with ML (chapter and AI. Make your decisions safe in the knowledge that you’ve been instructed by the best.
Updated: April 25, 2024